1.并行編程(1)并行程序的邏輯:1)將當(dāng)前問題劃分為多個子任務(wù)
2)考慮任務(wù)間所需要的通信通道
3)將任務(wù)聚合成復(fù)合任務(wù)
4)將復(fù)合任務(wù)分配到核上
(2)共享內(nèi)存編程:
- 路障 ----> 條件變量,互斥量+忙等待(浪費cpu周期,重置),信號量(多個路障產(chǎn)生競爭條件)
- 臨界區(qū)(更新共享資源的代碼段)------>忙等待(標識變量),互斥量,信號量(信號量沒有個體擁有權(quán)),讀寫鎖
- 共享內(nèi)存帶來的問題:緩存一致性,線程的安全性,多個線程嘗試更新一個共享變量的時候會產(chǎn)生問題(競爭條件)
- 線程是否越多越好:否,由于線程的切換和可能導(dǎo)致的二義性 。
- 線程和進程:線程是輕量級的進程,由進程派生,共享進程的大部分資源,但擁有獨立的程序計數(shù)器和函數(shù)調(diào)用棧
- 局部性原理
- 空間局部性
- 時間局部性
- 空間局部性
- 串行部分決定了加速比的上限
- 矩陣加減
template <class T>T** add_sub(int n1,int m1,int n2,int m2,T **a,T *bb,int flag){T c[n1+10][m1+10];if(n1!=n2||m1!=m2){ cout<<"No Solution";return 0; }for(int i=1;i<=n1;i++)for(int t=1;t<=m1;t++)c[i][t]=a[i][t]+b[i][t]*flag;}- 矩陣乘法
template <class T>T** mul(int n1,int m1,int n2,int m2,T **a,T **b){ if(m1!=n2){ cout<<"No Solution";return 0; }T c[n1+10][m2+10];for(int i=1;i<=n1;i++)for(int t=1;t<=m2;t++)c[i][t]=0;for(int i=1;i<=n1;i++)for(int t=1;t<=m1;t++){for(int j=1;j<=m2;j++){c[i][j]+=a[i][t]*b[t][j];}}}- 矩陣除法
template <class T>T** div(int n1,int m1,int n2,int m2,T **a,T **b){T e[n1+10][n2+10];for(int i=1;i<=n2;i++){for(int t=1;t<=n2;t++){if(i==t) e[i][t]=1;else e[i][t]=0;}}//Gauss-Jordan消元法求矩陣的逆for(int i=1;i<=n2;i++){int max=i;for(int t=i+1;t<=n2;t++)if(fabs(a[t][i])>fabs(a[max][i])) max=t;if(fabs(a[max][i])<1e-10){cout<<"No Solution";return 0;}if(i!=max){swap(a[i],a[max]);swap(e[i],e[max]);}for(int t=1;t<=n2;t++){if(t!=i){double flag=a[i][i]/a[t][i];for(int j=1;j<=n2;j++){a[t][j]=flag*a[t][j]-a[i][j];e[t][j]=flag*e[t][j]-e[i][j];}}}}for(int i=1;i<=n2;i++){printf("%.2lf\n",a[i][n2+1]/a[i][i]);}return mul(n1,m1,n2,m2,a,e);}(2)矩陣乘法優(yōu)化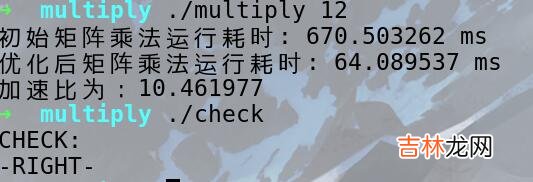
文章插圖
優(yōu)化方法
- 矩陣分塊(減少cache的缺失由于緩存容量的有限性)
- 矩陣的轉(zhuǎn)置(空間局部性原理)
- 指令集向量化:avx256
- 多線程:pthread
`for(int i=1;i<N;i++)for(int t=1+i;t<N;t++)swap(b[i][t],b[t][i]);N--;thread_count=strtol(argv[1],NULL,10);thread_count=10;flag=(N+thread_count-1)/thread_count;pthread_t *threads;threads=(pthread_t*)malloc(thread_count * sizeof(pthread_t));for(int i=0;i<thread_count;i++){int* id = (int*)malloc(sizeof(int));*id = i;pthread_create(&threads[i],NULL,matrixMul,(void* )id);}for(int i=0;i<thread_count;i++)pthread_join(threads[i],NULL);free(threads);`?`void *matrixMul(void *rank){__m256d a1,b1;__m256d z= _mm256_setzero_pd();int my_rank=*((int*)rank);int T=128;for(int l=1+flag*my_rank;l<=min(N,flag*(my_rank+1));l+=T)for(int r=1;r<=N;r+=T)for(int k=1;k<=N;k+=T)for(int i=l;i<=min(l+T-1,flag*(my_rank+1));i++){for(int j=r;j<=min(r+T-1,N);j++){for(int t=k;t<=min(k+T-1,N/4*4);t+=4){a1=_mm256_loadu_pd(&a[i][t]);b1=_mm256_loadu_pd(&b[j][t]);a1=_mm256_mul_pd(a1,b1);c[i][j]+=a1[3]+a1[2]+a1[1]+a1[0];}}}for(int i=1+flag*my_rank;i<=min(N,flag*(my_rank+1));i++)for(int j=1;j<=N;j++){for(int t=N/4*4+1;t<=N;t++){c[i][j]+=a[i][t]*b[j][t];}}}`
經(jīng)驗總結(jié)擴展閱讀
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- hplc是什么的簡稱
- hpl是什么材料
- 魅族16與16P的四點不同 魅族16plus和魅族16thplus一樣嗎
- 串行接口和并行接口 串行接口和并行接口的區(qū)別是什么?
- costudy軟件是干什么的?
- 人的一生總是苦與樂并行。|人的一生有三苦,若你能夠熬過去,那福運自然會降臨
- 這才是家家有本難念的經(jīng)的真正原因:理智和苦衷無法并行
- 時間寶貴 人要想活得好,就好好想想怎樣活,并行動
- study怎么讀 study怎么讀
- adobeflashplayer是什么 adobeflashplayer的簡介